Все операторы поиска яндекса: самый полный список
Содержание:
- Операторы поиска для Google
- Операторы поиска Google
- Популярные символы и операторы в «Яндексе»
- Место в алгоритме ранжирования
- Яндекс дорки?
- Операторы Яндекс.Поиска для SEO: как правильно и точно искать
- Полезные инструменты проверки количества запросов и ключевых слов
- Вспомогательные приёмы и операторы
- Информация
- Сравнение Палеха, Королёва и YATI
- Используем минус-слова для фильтрации нецелевых запросов
- 7 важных работ: тексты
- Факторы ранжирования
- Почему важно знать статистику поисковых запросов
Операторы поиска для Google
-
Оператор «..» две точки
— Используется для поиска диапазонов между числами. -
Оператор «@»
— Для поиска по тегам в соц. Сетях -
Оператор «#»
— Поиск по хештегам
Документные операторы Google
-
site:
аналогично Яндексу ищет по указанному сайту или домену -
link:
поиск страниц, ссылающихся на указанный сайт - related: поиск страниц со схожим содержимым
-
info:
С помощью этого оператора можно получить сведения о веб-адресе, в том числе ссылки на кешированную версию страницы, похожие сайты, а также страницы, ссылающиеся на указанную вами. -
cache:
просмотр кешированной версии страницы -
filetype:
поиск в указанных типах файлов, можно указать расширение -
movie:
поиск информации о фильмах -
daterange:
поиск страниц проиндексированных за указанный промежуток времени -
allintitle:
поиск страниц, у которых слова из запроса находятся в title -
intitle:
тоже самое, но часть запроса может содержаться и в другой части страниц -
allinurl:
поиск страниц, содержащих все слова запроса в url -
inurl:
тоже самое, но для одного слова -
allintext:
только в тексте -
intext:
для одного слова -
allinanchor:
поиск по словам в анкорах - inanchor:
-
define
: поиск страниц с определением указанного слова
Операторы поиска Google
-
Оператор «+» означает обязательное включение в поиск слов, указанных после +.
-
Оператор «-» исключает из поиска слово, указанное после -.
-
Оператор «””» означает поиск с вхождением фразы точно в указанной форме.
-
Оператор «OR» или его аналог «|» означает поиск со словами «… или …».
-
Оператор «AND» ищет результаты с запросами «… и …».
-
Операторы «#» или «@» означают поиск результатов с указанным хэштегом или ником.
-
Оператор «*» указывает на пропуск одного или нескольких слов в запросе. Удобно использовать, если вы помните только часть фразы.
-
Оператор «in» или «to» — конвертация числовых величин, в том числе валют.
-
Операторы «$» или «€» означают поиск товаров с ценой в указанной валюте.
-
Оператор «define:» определяет какое-либо понятие, ищет его в словарях.
-
Операторы «filetype:» или «ext:» выдают результаты по запросу в указанном файловом формате. После нажатия начнётся скачивание файла.
-
Оператор «site:» ищет заданную фразу на конкретном сайте. Если ввести оператор без поискового запроса, вы получите список всех проиндексированных страниц указанного сайта.
-
Оператор «source:» тоже выдаёт ссылки с запросами из указанного источника. Они занимают первые позиции в выдаче, дальше идут альтернативные ссылки с вхождением указанного запроса и его источника.
-
Операторы «intitle:» и «allintitle:» выдают результаты с вхождением одного слова или фразы в заголовке страницы. Если нужно найти несколько слов — используйте «allintitle:».
-
Операторы «inurl:» и «allinurl:» выдают результаты с вхождением одного слова или фразы в URL. Для поиска нескольких слов используйте «allinurl:».
-
Операторы «intext:» и «allintext:» выдают результаты с вхождением слова или фразы в тексте на странице.
-
Оператор «related:» находит сайты с похожим по тематике контентом.
-
Оператор «cache:» вызывает из кэша последнюю версию указанной страницы, если она была проиндексирована. Вот что появляется, если в поисковую строку ввести «cache:text.ru».
-
Рассмотрим пример комбинирования операторов. Найдём страницы с точным вхождением запроса «Дэвид Огилви» на сайте «loveread.ec».
-
Иногда при использовании операторов Google выдаёт неточные результаты. Так происходит, если поисковик определяет более оптимальный / правильный результат. Например, если указать СЕО в запросе, результаты будут включать заголовки и текст с вхождением SEO.
Популярные символы и операторы в «Яндексе»
Восклицательный знак. Предназначен для фиксации формы поискового слова. То есть поисковик будет искать текст, в котором есть слово в указанном пользователем падеже, числе, времени. Вводить оператор следует перед ключевым словом.
Кавычки. Они используются для поиска текста, содержащего точное количество слов в поисковой фразе. Для применения нужные слова следует взять в кавычки.
Амперсанд. Его используют для поиска ключевых слов в одном предложении. Если поставить символ & между словами, то поисковик будет искать текст, в котором есть предложение, содержащее введенные поисковые слова.
Скобки квадратные. Предназначены для указания порядка слов в поисковой фразе.
Скобки круглые и вертикальная черта. Оператор используют для группировки вариантов слов в поисковой фразе.
Поисковые операторы Яндекса
Операторы поиска Яндекс
title=
Место в алгоритме ранжирования
Это важный момент. Нужно понимать, что нейронная сеть не пришла на замену всей формуле ранжирования. Она является по сути одним из факторов, которые вычисляются и используются для построения итоговой формулы релевантности (Cat Boost).
Cat Boost пришел на замену MatrixNet – это алгоритм машинного обучения на решающих деревьях, который во многом нам близок.

Тот фактор, который вычислен по алгоритму YATI, является одним из факторов, на котором строится итоговая формула ранжирования.
Важный момент: итоговая формула ранжирования все равно строится алгоритмом Cat Boost, а не оперирует какими-то нейронными сетями – это не итоговый ответ релевантности.
Пример «смешанной» выдачи
В таких случаях один из факторов «тянет» в свою сторону. В каком-то смысле это можно воспринимать как борьбу между теми факторами, которые отвечают за смысл, и теми, которые отвечают за «обычные вхождения» в текст. При этом понятно, что в борьбе принимают участие все остальные группы факторов:
- поведенческие;
- хостовые (сайт);
- ссылочные.
В результате выдача носит смешанный характер, как на примере с фразой «картина, где небо закручивается»:
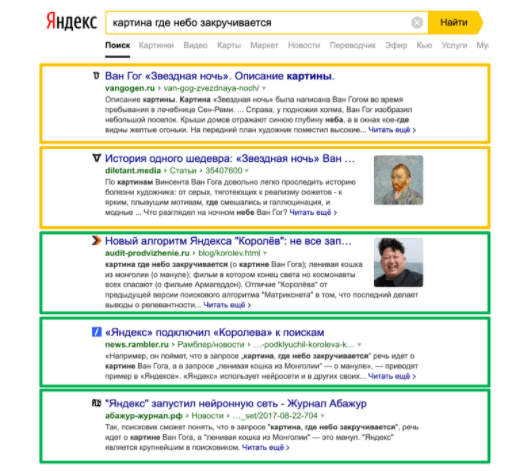
По запросу находятся результаты, в которых нет точного вхождения слов, но есть фразы, похожие по смыслу – например, картина «Звездная ночь» Ван Гога. Также присутствуют документы, в которых есть точное вхождение запроса. Здесь максимально ярко проиллюстрирована борьба нейронной сети со смыслом, с классическими SEO-шными факторами.
Достаточно хорошо видно, что Яндекс строит все не по принципу «мы придумали какой-то новый фактор, который теперь будет описывать смысл и смысловую близость запроса и документа», а по принципу «давайте добавим к текущим факторам набор дополнительных рычагов, которые будут улучшать выдачу».
Посмотрим на еще один пример «доминирования смысла», когда есть большое количество документов (в данном случае 24) с точным вхождением длинной фразы «фильм про человека, который выращивал картошку на другой планете». Поисковая система понимает, что речь идет о фильме «Марсианин», находит документы без прямого вхождения, а иногда и вовсе без вхождения прямых слов. В этом случае смысл побеждает.
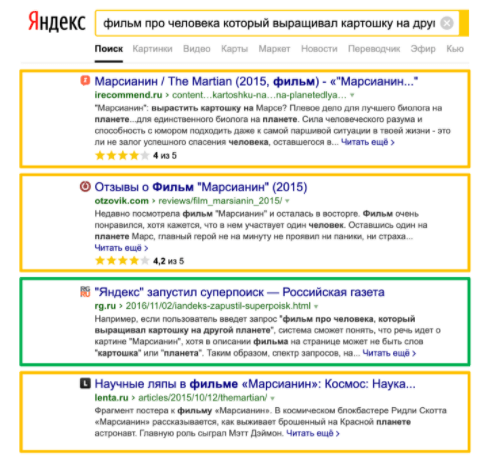
Но когда добавляют хостовые факторы, как например у «Российской газеты», достаточно прокачанной с точки зрения хоста, в выдачу также попадает документ с точным вхождением, абсолютно не оптимизированный, не посвященный фильму!
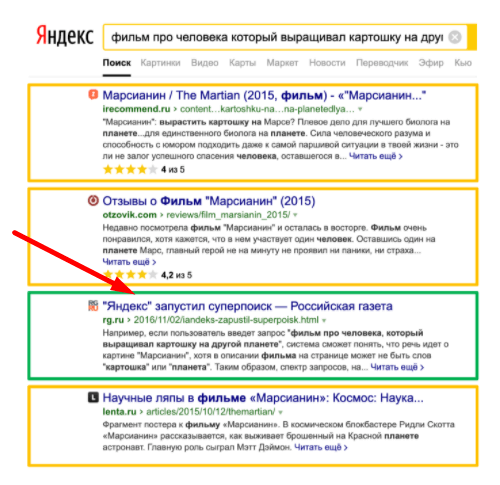
Отсюда исходит очень важный вывод, на который мы хотели бы обратить ваше внимание:

Приведенные выше примеры – это примеры из анонсов алгоритмов Палеха и Королева, где Яндекс говорит примерно такие вещи: «Мы придумали поисковый запрос, видим, что по нему была нерелевантная выдача, а теперь она стала релевантной». То есть по запросу «фильм про человека, который выращивал картошку на другой планете» в выдаче есть фильм «Марсианин». Как только Яндекс это анонсировал, большое количество сайтов растиражировали новость. Алгоритм ломался, так как поисковая система продолжала отдавать предпочтение классическим вхождениям в текст.
На наш взгляд, YATI – это тот самый момент, когда факторы смысла и смысловой близости запросов документа стали побеждать факторы вхождения, что очень хорошо видно на низкочастотных поисковых запросах.
Яндекс дорки?
Поиск в Яндекс, безусловно, может оказаться полезным для исследователей на основе открытых источников. В том числе, при поиске утечек.
А как насчёт поиска в Яндекс для хакеров и пентестеров? Хотя язык запросов Яндекса менее гибок, всё равно и через Яндекс можно найти разнообразную чувствительную информацию и файлы, не предназначенные для всеобщего доступа.
Брутфорс поддоменов по одной букве
Мы уже рассматривали как с помощью Гугл перечислеть поддомены. Там же я говорил про плюсы и минусы этого способа. В Яндекс тоже есть такая возможность. Причём, для тех сайтов, которые я попробовал, Яндекс знает больше субдоменов чем Google!
Для этого можно использовать оператор rhost: Напомню, при нём домен/поддомен пишется в обратном порядке, т.е. начиная с домена верхнего уровня, затем домен второго уровня, затем поддомен третьего уровня и так далее.
Самое интересное – используя подстановочный символ * мы можем искать по части поддомена – к слову, Google не воспринимает частично написанные домены вообще.
Допустим, меня интересуют поддомены сайта kali.org. Я делаю запросы вида:
rhost:org.kali.a* rhost:org.kali.b* rhost:org.kali.c* rhost:org.kali.d* rhost:org.kali.e* rhost:org.kali.f* rhost:org.kali.g* rhost:org.kali.h* rhost:org.kali.i* … rhost:org.kali.t* … …
В результате я нашёл несколько новых субдоменов, которые не смог найти с помощью Гугл:
- buildd-amd64.kali.org
- eros.kali.org
- eos.kali.org
- iris.kali.org
- images.kali.org
Можно создать скрипт и при правильно написанном алгоритме можно получить весь список субдоменов за несколько десятков запросов либо сотен запросов (в зависимости от выбранного алгоритма) – это может конкурировать с брут-форсом субдоменов по словарю
Самое важное – кроме Яндекса запросы никуда больше не делаются.
Аналогично для offensive-security.com с помощью Яндекса я нашёл субдомены, о которых не знал Гугл:
rhost:com.offensive-security.d*
download.offensive-security.com
rhost:com.offensive-security.f*
forums.offensive-security.com
rhost:com.offensive-security.i*
images.offensive-security.com
rhost:com.offensive-security.s*
- support.offensive-security.com
- screenconnect.offensive-security.com:8040
Поиск папок с открытым листингом
"Index of /" "Parent Directory"
В таких папках может быть что угодно – от публичных файлообменников до личных фото архивов.
Иногда там можно найти файлы со списком паролей:
Причём разных пользователей:
Пробуйте разные названия папок. Например, поиск папки admin листингом файлов:
"Index of /admin" "Parent Directory"
Поиск папки mail (иногда в них лежат электронные письма):
"Index of /mail" "Parent Directory"
"Вход" url:."ru/admin"
Или
"Вход" url:."ru/login"
Пробуйте свои варианты!
Операторы Яндекс.Поиска для SEO: как правильно и точно искать
-
Как правильно искать в Яндексе
- Что учитывается в запросе
- Синтаксис поиска
-
Символы для поиска
Не используйте устаревшие знаки
-
Документные операторы Яндекс.Поиска
- Поиск по всему сайту и поддоменам site:
- Поиск по начальному адресу url:
- Поиск по страницам главного зеркала сайта host:
- Поиск по хосту наоборот rhost:
- Поиск по сайтам на домене или в доменной зоне domain:
-
Фильтры расширенного поиска
- Фильтрация поиска по документам определённого формата mime:
- Фильтрация поиска документов по языку lang:
- Фильтрация страниц по дате изменения date:
- Бонус: как узнать дату первой индексации страницы в Яндексе
- Выводы
Язык поисковых запросов Яндекса включает в себя специальные символы и операторы поиска, которые можно использовать для уточнения или фильтрации результатов.

Стоит отметить, что язык Яндекса отличается не только от языка других поисковых систем (Google, Bing), но и внутри собственных сервисов (Поиск, Вордстат, Директ). Это значит, что операторы или спецсимволы, которые работают в одном сервисе, могут не функционировать в другом. Например, круглые скобки ( ) для группировки сложных запросов в Поиске не работают, но широко применяются в Wordstat и Директе.
Сегодня мы покажем на примерах полезные команды именно для точного Яндекс.Поиска. Правильно используя язык запросов, вы сможете легко искать страницы с точным вхождением слов, фильтровать результаты выдачи по региону или дате, а также находить технические проблемы на своём сайте.
Полезные инструменты проверки количества запросов и ключевых слов
Key Collector
Самый популярный сервис сбора ключевых слов и формирования семантического ядра. Распространяется на платной основе. Им пользуются профессионалы в области поисковой оптимизации.

Для первичной настройки программы требуется проделать следующее:
- Добавьте в Key Collector до 10 аккаунтов Яндекс.
- Добавьте в программу сервис анти-капчи. Настройки — Анти-капчи.
- Проведите настройку Вордстат. Настройки — Парсинг — Yandex.Wordstat.
Key Collector позволяет парсить десятки страниц и эффективно выгружать очищенные запросы в неограниченном количестве. Для работы сервиса парсинг производится в Яндекс.Директ.
Также доступен сбор статистики для Google Ads и социальных сетей. Для этого проведите настройки согласно инструкции на сайте разработчика.
Когда парсинг завершён, и вы работаете со списком слов, воспользуйтесь функцией фильтрации. Она помогает очистить выборку от неподходящих фраз и даже оставить только некоторые словоформы, удалив часть того или иного слова.
Также фильтрация помогает удалить повторяющиеся слова — для этого предусмотрена отдельная функция. Затем вы можете удалить специальные и нежелательные символы, такие как цифры и латинские буквы. Более того, если вам знакомы регулярные выражения, это окажется плюсом, так как они поддерживаются программой.
Один из важных этапов сбора семантического ядра — удаление стоп-слов. Эта функция реализована в Key Collector. Например, вы можете удалить лишние прилагательные, описывающие второстепенные свойства продукта: самый, лучший, красивый. Сюда относятся и свойства цены: недорогой, бесплатный, купить.
Поиск ключевых слов используют не только для продвижения страниц, но и при анализе работы менеджеров колл-центра. Технология речевой аналитики Calltouch Предикт переводит все разговоры операторов с клиентами в текстовую переписку, где вы можете в два клика найти нужное ключевое слово во всех склонениях, спряжениях, падежах и частях речи. Это помогает проследить, следует ли сотрудник скрипту продаж или как клиент употребляет определенную фразу.
Предикт
Автоматически определяет тип обращения
- Выявляет и тегирует сомнительные звонки от недобросовестных рекламных подрядчиков или спам
- В основе технологии: распознавании речи, машинное обучение и лингвистический анализ
- Позволяет анализировать продвижение отдельных направлений
Slovoeb
Данное приложение позволяет проводить парсинг ключевых слов и сбор частотности определённых запросов. Это бесплатное приложение, которое анализирует выдачу через Яндекс.Директ. Чтобы начать работу, так же, как и в случае с Key Collector, настройте Яндекс аккаунты и анти-капчу.
Функционал программы повторяет концепцию Key Collector, так как является предтечей последнего, и содержит урезанный функционал. Если вам интересно профессионально заниматься SEO, приобретите Key Collector. В случае грамотного использования вложения окупятся весьма быстро.

Ahrefs
Сервис Ahrefs предлагает инструмент Keywords Explorer для анализа ключевых слов. Он поддерживает поиск по 3 миллиардам ключевиков, более 100 стран, статистику кликов, анализ SERP и целый ряд полезных функций для фильтрации слов.
Добавьте через запятую интересующие вас запросы, выберите регион и запустите анализ. Или используйте сквозную аналитику Calltouch.
Сквозная аналитика
от 990 рублей в месяц
- Автоматически собирайте данные с рекламных площадок, сервисов и CRM в удобные отчеты
- Анализируйте воронку продаж от показов до ROI
- Настройте интеграции c CRM и другими сервисами: более 50 готовых решений
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Кастомизируйте таблицы, добавляйте свои метрики. Стройте отчеты моментально за любые периоды
Узнать подробнее
Keyword Tool
Это маркетинговый инструмент, который помогает в поиске ключевых слов и работает с функцией автозаполнения Google. Он генерирует сотни ключевых слов, одинаковых по значению, но отличающихся по форме. С помощью функции автозаполнения пользователи быстрее могут найти информацию в поисковике на основании предложенных системой слов. Keyword Tool оценивает подсказки, выдаваемые поисковиком, и структурирует их в удобном для пользователя виде.

Вспомогательные приёмы и операторы
Ещё большие возможности при работе с WordStat от Яндекса открываются с применением пяти дополнительных операторов. Это:
-
Оператор «Или» — задается скобками и символом «|». Оператор полезен, когда требуется сравнить или «смещать» несколько фраз в статистике, а также для быстрого подбора семантики на страницу.
-
Оператор «Квадратные скобки» — задается символами «[]» между которым заключена фраза. Позволяет зафиксировать порядок следования слов в запросе. Важен для оценки популярности близких фраз, особенно по частотным запросам.
-
Оператор «Плюс» — задается символом «+» и полезен, когда требуется найти поисковые запросы со стоп-словами (предлогами, союзами, частицами).
-
Оператор «Минус» — задается символом «-» и полезен, когда требуется исключить запросы с использованием ряда слов.
-
Оператор «Группировка» — задается символами скобки «()» и полезен, когда требуется сгруппировать использование описанных выше операторов.
Информация
По информационным запросам Яндекс и Google выглядят примерно одинаково. У российского поисковика есть преимущество в том, что он показывает пресс-портреты по имени и фамилии персоны, IP пользователя и погоду по однословному запросу . Западный поисковик ни одной из этих функций. Google ведет себя адекватнее при запросе, содержащем слово «новости», выдавая вверху выдачи . Яндекс чаще новости на подобные запросы.
|
Действие |
Яндекс |
|
|
Погода в своем городе |
— |
|
|
Погода в каком-либо городе |
||
|
Пресс-портреты |
— |
|
|
Новости |
— |
|
|
Маркет |
glofiish x600 |
— |
|
Финансовые и биржевые показатели |
— |
|
|
Адрес собственного IP |
— |
|
|
мой айпи |
— |
|
|
Карта по адресу |
||
|
Карта города |
Сравнение Палеха, Королёва и YATI

Палех. Был запущен с кардинально другой архитектурой с точки зрения машинного обучения и нейросетей. Учитывается только запрос и заголовок документа. В обучение было загружено миллион слов из словаря, миллион биграмм слов и буквенные триграммы. Таким образом, слова разбивались на «трибуквия», в том числе, чтобы понять, что слова «большой» и «большущий» близки друг другу. Также грузить триграммы полезно для опечаток. Полностью алгоритм ранжирования использовался только для первых 150 «лучших» документов. В процессе отборки могут быть потеряны документы, которые могли бы попасть в ТОП-10.
Королёв. Использовал ту же основу, что и Палех, при этом частично учитывал текст запроса, некоторые важные зоны. Здесь уже появляются стримы, когда мы анализируем с помощью нейронной сети не только сам запрос и сам документ, но и используем так называемый запросный индекс для URL-адреса (не только показы, но и клики). Алгоритм используется для большего количества документов – порядка 200 тысяч, которые прошли предварительные этапы ранжирования.
YATI. Имеет принципиально другую архитектуру, еще больше стримов, то есть используется анкор-лист документа, запросный индекс для URL-адреса по кликам. Присутствует большая полнота данных в учете – тексты до 10 предложений, по заверениям авторов алгоритма, учитываются целиком.
К слову, 10 предложений – не так уж много. Если текст больше, то он будет разбиваться на важные фрагменты и показываться нейронной сети. Какие документы важные – определяет отдельный алгоритм, важен ли этот фрагмент для ранжирования – определяет нейронка.
Используем минус-слова для фильтрации нецелевых запросов
При проверке фразы в Вордстате сервис покажет поисковые запросы, которые могут содержать нерелевантные слова. Такие слова желательно исключить, чтобы оценить чистый спрос на вашу услугу или товар.
Эту фразу пользователи ищут примерно 690 тысяч раз в месяц. При этом запросы с этой фразой иногда содержат слово «недорогой».
Если такой запрос для нас является нецелевым (например, вы продаете только геймерские ноутбуки с топовой начинкой), его лучше исключить из статистики.
Для этого используем минус-слова. Вводим в поисковую строку Вордстата запрос «купить ноутбук» и добавляем минус-слово «-недорогой». Жмем «Подобрать» и видим: количество запросов стало меньше, а в блоке «Что искали со словом» — нет результатов, содержащих слово «недорогой».
Также к основной фразе можно добавить несколько минус-слов, чтобы исключить другие нерелевантные запросы. Посмотрите запросы из левой и правой колонок, найдите слова или фразы, которые вам не подходят, и укажите их в качестве минус-слов.
На выходе вы получите чистые данные по релевантным запросам, что поможет качественно оценить спрос.
Какие группы слов часто используют в качестве минус-слов в контекстной рекламе:
- DIY-слова — «сделать», «своими руками», «самостоятельно» и т. д.;
- маркеры информационных запросов («почему», «как», «чем», «какой» и т. п.);
- слова «мусорного» спроса — «бесплатно», «giveaway», «в дар» и т. п.
- маркеры вторичного рынка — «бу», «подержанный»;
- характеристики или свойства продукта, которые не подходят для вашей кампании. Например, если вы продаете только мужские кроссовки, исключите из статистики слова «женские» и «детские».
Операторы поиска: уточняем статистику по запросам
С помощью операторов поиска можно уточнить запрос и посмотреть точную статистику показов по фразе в нужной форме или с определенным порядком слов. Использование операторов доступно в разделах «По словам» и «По регионам».
Кавычки » » (фиксация слов)
При указании запроса в кавычках вы увидите статистику только по указанному словосочетанию (без добавления других слов). При этом порядок слов и окончания могут меняться.
Восклицательный знак! (фиксация словоформы)
Используется для фиксации окончания в указанном виде и размещается перед словом, в котором его нужно зафиксировать.
Обратите внимание! Используйте оператор «кавычки» совместно с оператором «!». Так вы сможете узнать точную частотность любого запроса
Плюс + (фиксация стоп-слов)
Используется для проверки частотности по запросам, содержащим стоп-слова (служебные части речи, местоимения и др.). По умолчанию в Яндекс.Вордстате они не учитываются. Например, если мы введем в Вордстате фразу «двери для», сервис покажет статистику без учета предлога «для».
Сравните сами. По запросу «двери» сервис показывает 9 631 111 показов в месяц:
А вот статистика по запросу «двери для» (результат аналогичный):
А теперь фиксируем стоп-слово «для» и получаем уже 831 973 показов в месяц, а не 9 631 111.
Вертикальный слэш | (логический оператор «или»)
Применяется для объединения статистики по разным запросам. Например, если мы продаем входные двери, полезно узнать количество запросов от владельцев квартир и загородных домов. Для этого используем оператор | — вводим в Вордстате такую фразу:
В результатах подбора будет статистика по запросам, содержащим любое из словосочетаний, указанных в круглых скобках.
Квадратные скобки [] (фиксация порядка слов)
При использовании этого оператора система покажет статистику по запросам, в которых содержатся указанные слова в заданном порядке.
Использование [] поможет исключить запросы с иным порядком слов и зафиксировать нужный порядок слов
Это важно, например, если вы рекламируете продажу билетов по конкретным направлениям
7 важных работ: тексты
Переходим к рекомендациям – семи важным работам, которые нужно делать SEO-специалисту для оптимизации под алгоритмы YATI, чтобы позиции росли.
1. Оптимизируйте под YATI.
Раньше эти рекомендации касались оптимизации под «Королёв» и «Палех». Нам нужно максимизировать количество слов из продвигаемого поискового запроса, которые встречаются в контексте. То есть мы задаем поисковый запрос «пластиковые окна» и должны максимизировать количество слов, которые встречаются в контексте с этой фразой, отдельно взятыми этими словами в поисковой системе. Мы предлагаем делать это с помощью инструмента «ТЗ для копирайтера», там используются:
- прямые синонимы, которые давно учитываются;
- слова из подсветки выдачи;
- слова, задающие тематику – часто встречаются в документах, но не совпадают с поисковыми словами из запроса;
- слова, которые встречаются у конкурентов, но их нет на продвигаемой странице: «Анализ ТОП по ключевым показателям».
2. Форматирование текста на фрагменты и акценты.
Мы знаем, что алгоритм выделяет определенные важные зоны в тексте и подает их на вход нейронной сети, чтобы она оценила, близок этот фрагмент по смыслу к поисковому запросу или нет, помогает он пользователю или нет. Форматировать тексты нужно обязательно, а именно:
- разбивать подзаголовками и заголовками, начиная примерно с 10–12 предложений;
- выносить тематические и ключевые слова в заголовки и выделенные фрагменты.
То есть слова, задающие тематику, должны быть в тех фрагментах, которые с большой долей вероятности подадутся на вход нейронной сети – это заголовки и небольшие выделенные фрагменты.
3. Анализируйте и оптимизируйте запросный индекс для документов.
Эта информация уже не раз озвучивалась в предыдущих рекомендациях, значимость этого фактора растет. Что нужно делать:
- изучите поисковые запросы, по которым были зафиксированы переходы на URL, они должны быть релевантными. Если вы видите, что переход на URL-адрес осуществляется по нерелевантным поисковым запросам, нужно что-то с этим делать – деоптимизировать страницу, убрать какие-то слова с точки зрения контекста;
- поднимите релевантность по тем запросам, по которым уже были переходы, чтобы повысить позицию исходного поискового запроса. Это стандартная схема от НЧ для документа к СЧ/ВЧ.
4. Запросный индекс для хоста.
Важные моменты здесь:
- данные для хоста, как и прежде, сказываются на факторах для заданной страницы;
- проверки из пункта №3 выше актуальны и в разрезе всего сайта, а не только заданного URL.
5. Расширяйте семантическое ядро для продвижения в сторону низкочастотных запросов.
Это обязательно должны быть вложенные и синонимичные запросы, они помогают в продвижении по более общим и близким по смыслу высокочастотным запросам. Пример: поможет и для и для . Слова «продвижение», «SMM», «SEO» с точки зрения Яндекса – это довольно близкие термины, которые часто сравниваются друг с другом.
6. Проводите конкурентный анализ.
Наше видео по теме «Анализ ТОП и конкурентв для SEO: 7 шагов шаблон инструменты автоматизации» и .
Что вы можете посмотреть:
- показы конкурентов по запросам;
- акценты на текстах: тематические слова, фразы, структура;
- структура сайта и охват запросов из семантического ядра.
Если у конкурента какой-то поисковый запрос охвачен всецело (под него есть целый раздел, развернутая структура по тегам), то вам нужно повторить эту развернутую структуру, чтобы полноценно ее охватить. Анализ конкурентов – сквозная тема в любом SEO.
7. Не забывайте про классику поисковой оптимизации: текст, точные вхождения, все слова в Title.
- Как мы поняли из результатов исследования, она никуда не ушла. YATI хоть и является прорывной технологией, Яндекс все же строится по принципу «добавить что-то сверху», а не «написать все с нуля». То есть никто не отменял алгоритмы Яндекса и не говорил, что будет писать кардинально новый алгоритм, в котором не будет TF-IDF, BM25, просто новые добавляются к старым.
- Роль смысловой близости текста и запроса растет, если у поисковой системы нет или мало данных о поведении по данному запросу и мало документов, которые «хороши» по классическим текстовым факторам.
- Максимальный прирост идет по неоднозначным редким поисковым запросам («длинным хвостам») – то, на что все алгоритмы и направлены. Здесь нет никаких революционных изменений с точки зрения поисковой оптимизации и на текущий момент не предвидится. Это исходит из того, что Яндекс плюс-минус доволен качеством выдачи, за исключением кейсов с накрутками.
- На вход YATI подаются различные стримы: анкор-лист документа и запросный индекс по кликам.
Факторы ранжирования
Стоит отметить, что поисковые системы не раскрывают до конца все критерии ранжирования сайта и технологии определения релевантности. Даются лишь общие рекомендации, главная суть которых – улучшение качества контента, его содержательности и полезности для конечного пользователя. К числу основных факторов относятся следующие:
Тем не менее часто на первой странице выдачи можно наблюдать материалы, которые далеки от таких требований и занимают их благодаря использованию технологий «черного SEO». Однако такие ресурсы обычно исключаются из выдачи с применением санкций при очередной модернизации алгоритмов ранжирования. Впрочем, нередки и ситуации, когда внедрение нового алгоритма приводит к понижению позиций качественных ресурсов, что требует постоянного внимания к ним со стороны их владельцев и своевременного реагирования оптимизаторов на изменение ситуации, чтобы не допустить потери прибыли из-за снижения потока клиентов от поисковых систем.
Почему важно знать статистику поисковых запросов
Создавая страницы в интернете, их авторы рассчитывают на то, чтобы они стали популярными. Это касается, как сайтов, так и аккаунтов в соцсетях и других сервисов, на которых пользователям предлагается какой-либо контент или услуги.
Существует множество факторов, влияющих на популярность сайтов и страниц. Одним из основных является то, насколько легко ваш ресурс находят пользователи через запросы в поиске. Оптимизация по поисковым запросам играет роль в нескольких ситуациях:
- Создание сайта. Чтобы обеспечить индексацию ресурса по поисковым запросам, начните с определения релевантных и распространённых запросов, через которое максимальное число людей сможет найти ваш сайт.
- Создание страницы на портале. Это может быть персональная страница в соцсети или страница бренда на агрегаторе услуг. В каждом случае страницу необходимо наполнять ключевыми словами. По ним пользователи легче найдут вас.
- Настройка рекламы. Настройка рекламы начинается со сбора семантического ядра. Это список фраз, которые приведут пользователя на ваш сайт. Ключевые слова из семантического ядра учитываются поисковой системой, в рамках которой настраивается реклама. Когда кто-то вводит в строку слова, указанные в вашем семантическом ядре, поисковая система включает ваши страницы в выдачу пользователя. Позиции в ней зависят от ряда факторов — например, поведенческих, о которых мы писали недавно.
В каждом из этих случаев требуется провести сбор и анализ ключевых запросов.
Запуская рекламную кампанию, рекомендуем выбирать сервисы автоматизации. Качественные кампании состоят из множества ключевых слов, управлять ставками которых в режиме нон-стоп почти невозможно. Задачу автоматизации легко решает, например, Оптимизатор Calltouch.
Оптимизатор
Эффективный инструмент по оптимизации и автоматизации контекстной рекламы
- Забудьте про ручное управление ставками, машинное обучение сделает все за вас
- Полная интеграция с Яндекс.Директ и Google Adwords
- Автоматическая оптимизация ставок для получения большего количества лидов
- Бесплатно для клиентов Calltouch